Let's look at books vs. weight of cow
Is there a relationship between length of book (Q5) and estimates on weight of cow (Q6)?
Making a scatter plot to explore
w1df %>% select(Q5:Q6) %>% ggplot(aes(x = Q5, y = Q6)) + geom_point() + theme_minimal() + labs(x = "Pages", y = "Weight of Cow", title = "Kick Ass Scatterplot!")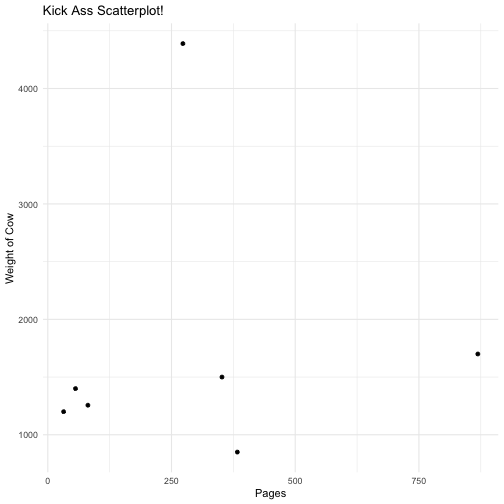
A residual is the distance between the Y value for each measurement, and the predicted Y value.
Let's investigate the residuals for our data
w1df %>% select(Q5,Q6)## # A tibble: 7 × 2## Q5 Q6## <dbl> <dbl>## 1 273 4389## 2 32 1200## 3 383 850## 4 352 1500## 5 869 1700## 6 56 1400## 7 81 1256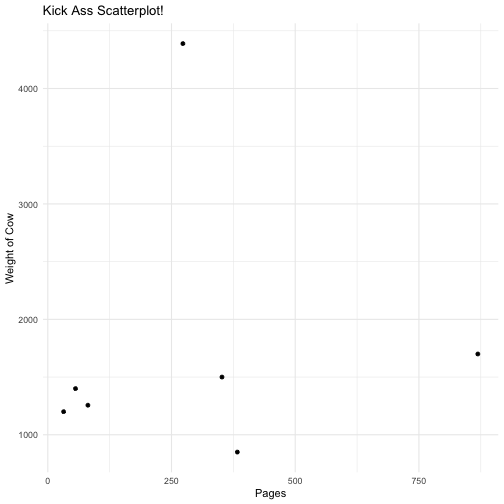
Let's check out those residuals...
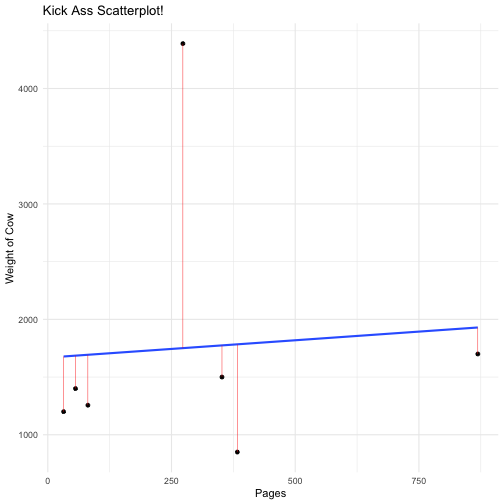
augment(Model1) %>% select(Q5:.resid)## # A tibble: 7 × 3## Q5 .fitted .resid## <dbl> <dbl> <dbl>## 1 273 1751. 2638.## 2 32 1678. -478.## 3 383 1784. -934.## 4 352 1774. -274.## 5 869 1929. -229.## 6 56 1686. -286.## 7 81 1693. -437.